Zotero是一款开源、跨平台的知识管理软件。
本系列将介绍如何使用Zotero,搭建最佳的文献生态,服务于我们的科研工作。Zotero官方网站提供下载。
Zotero软件优点
- 在浏览器端利用Zotero Connector,可以实现对各大主流数据库(Web of Science、Pubmed、ScienceDirect等)或搜索引擎(Google Scholar、百度学术、Research Gate等)具有文献一键抓取能力,甚至支持豆瓣图书的抓取。抓取内容包括文献元数据、PDF、网页链接等。
- 跨平台实时同步功能,便于随时随地在多平台访问文献。
- 可与第三方云存储(如坚果云)绑定,达到无限扩展Zotero存储空间的目的,在我看来这是Zotero最具特色的功能了,后面会专门介绍。
- 作为一款开源软件,Zotero的更新速度很快,保证了它的使用体验。Zotero占用空间很小,运行起来非常流畅,这一点比Endnote有优势。
- Zotero支持插件扩展,这使得Zotero更加强大,如PDF文件自动命名功能。
- Zotero提供分组、标签等功能,方便了我们对文献的管理。灵活使用标签功能,可以大大提高文献管理的效率。
- 提供Windows和Mac端的Office插件,方便学术论文写作。Zotero支持非常丰富的期刊参考文献格式,写论文时不用再愁了。
- Zotero还支持Rss订阅,这一功能使得Zotero能够把学术文献和各种其他资讯集中在一块,可以说融合了科研+生活。因此,Zotero构建的不仅是文献管理生态,更是一个知识生态。
Zotero入门
Zotero客户端配置
首先到Zotero官网注册一个Zotero账号。
启动Zotero客户端(本文以Mac版本示范,version 5.0.74),打开首选项设置Preferences,如下。
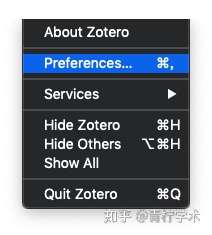
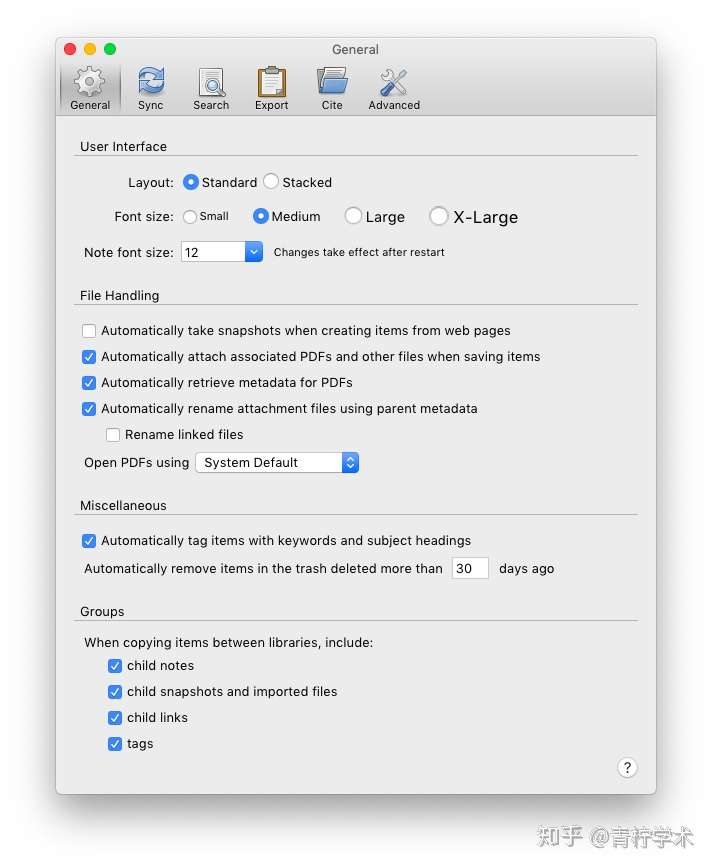
选择General,推荐按照如下设置。
选择同步(Sync),登录Zotero账户,如下。

这里需要注意的是,Zotero的存储包含数据信息和PDF附件,可以分别存储。其中,数据信息可以理解成包含元数据的文献列表。
由于Zotero的免费空间只有300M,而PDF文件占用的空间较大,因此这300M空间肯定是不够用的。
有钱任性的可以直接购买Zotero的空间,不过后面我会介绍如何使用坚果云作为WebDAV无限扩展Zotero的空间。
接下来介绍ZotFile插件的使用。ZotFile有很多功能,比如帮助自动命名PDF文件,即PDF文件会拥有一个统一的命名方式,这会为我们带来很大方便。
打开菜单栏Tools的安装插件选项Add-ons,如下。
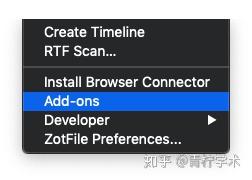
然后到网上(http://zotfile.com)下载Zotfile,并在下面的窗口中添加进去。
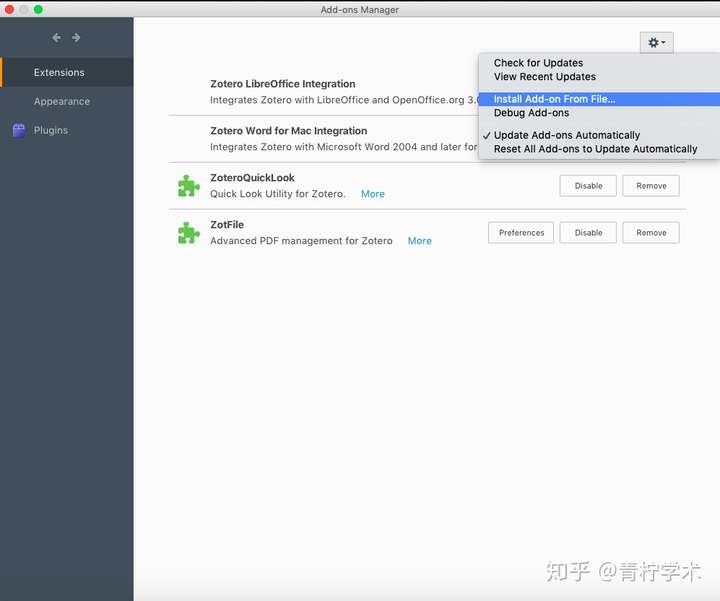
安装好后,在Tools菜单栏会出现ZotFile的设置选项,如下。
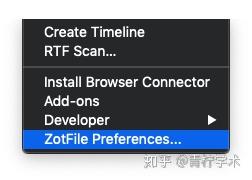
打开ZotFile Preferences,选择Renaming Rules,勾上Use Zotero to Rename。下面是按照作者_时间_标题的格式对PDF文件命名的,大家也可以按照自己的喜欢更改格式。
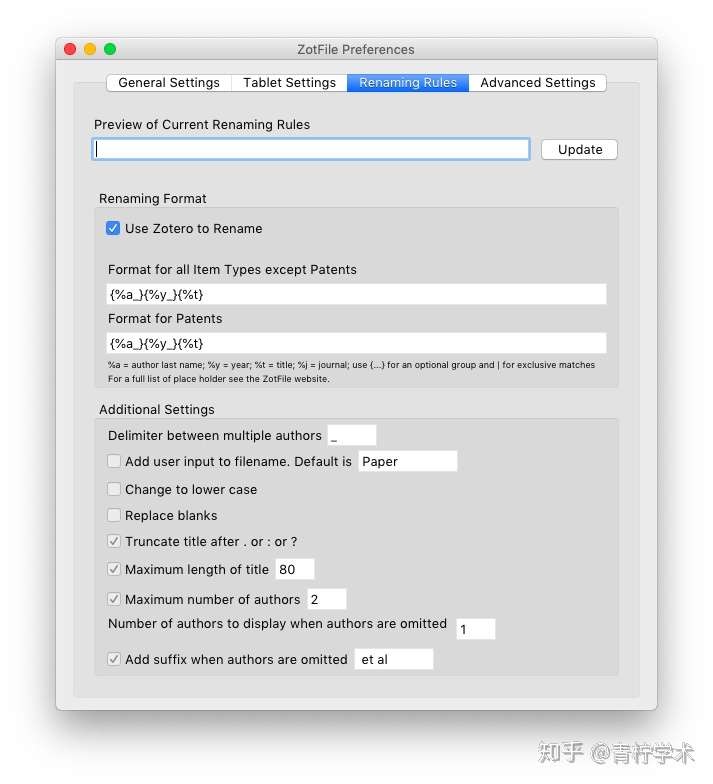
设置好重命名后,那么如何使用呢?任意选择Zotero的一条包含PDF附件的条目,按下图操作即可完成PDF文件的命名。

如何导入文献?
Zotero有多种导入文献的方式,比如:
- 网页识别
- 抓取PDF元数据
- 手动输入
- 通过标示符增加:Add by identifier (DOI, ISBN, PMID)
- 文件导入(比如从Endnote导入)
本篇文章重点介绍网页识别和PDF元数据抓取。
1. PDF元数据抓取
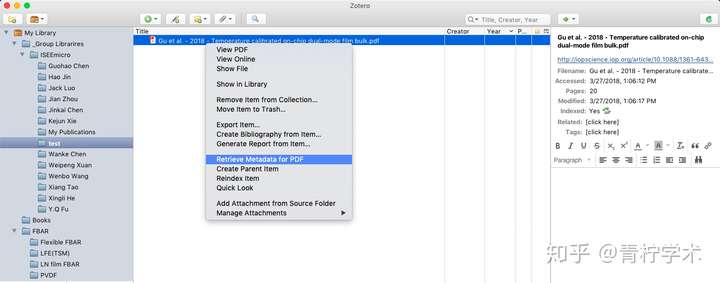
拖动一PDF文件到Zotero的某个分组中,右击该PDF文件,选择“retrieve metadata for PDF”,如下。
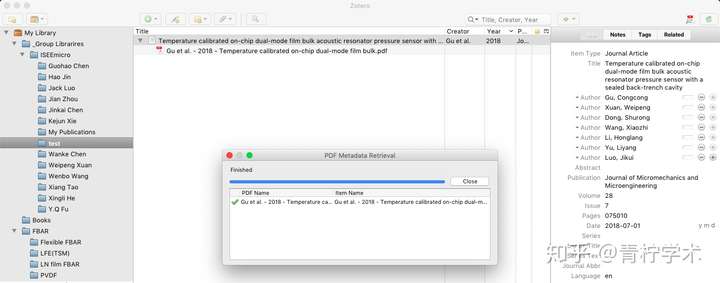
如果抓取成功(注意,Zotero只能抓取英文文献的PDF文件,中文文献可以通过其他方式导入),结果如下所示。
2. 网页抓取
要想做到网页抓取,需要首先安装Zotero Connector浏览器插件。下面以安装好插件的Chrome浏览器示范Zotero对不同数据库的网页抓取能力。
a. Google scholar
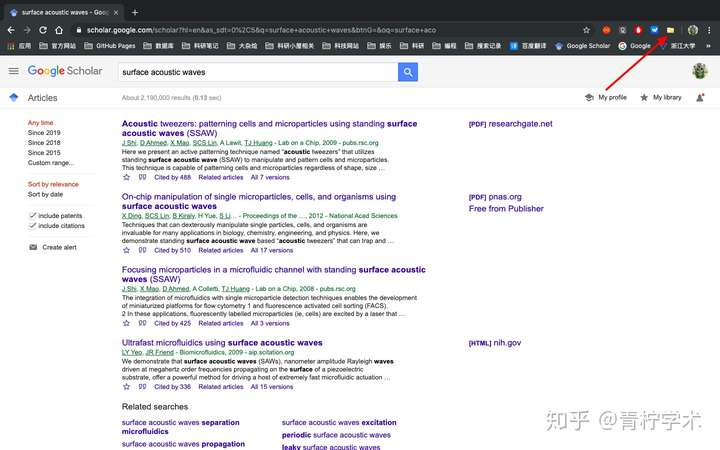
由于Zotero支持对谷歌学术搜索结果的识别,因此当我们在谷歌学术搜索文献后,插件形状会变成文件夹的图标,点击该图标,即可选择导入哪些文献到Zotero中,默认导入到当前被选中的分组中。

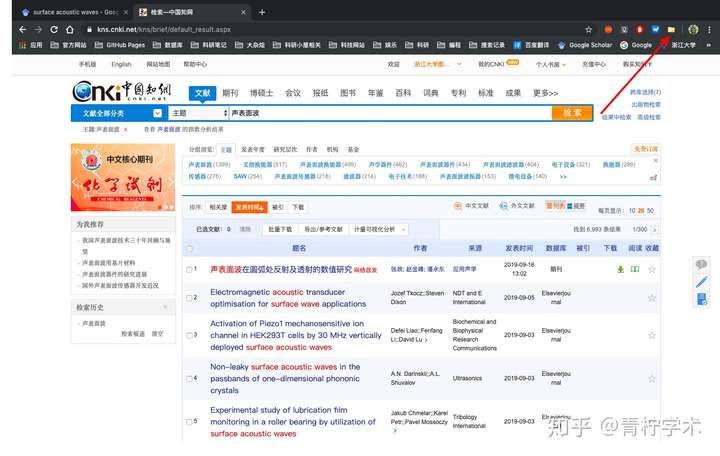
b. 中国知网
很多人可能需要保存中文文献的需要,幸运的是Zotero能够识别中国知网。如下图所示,其他操作类似。
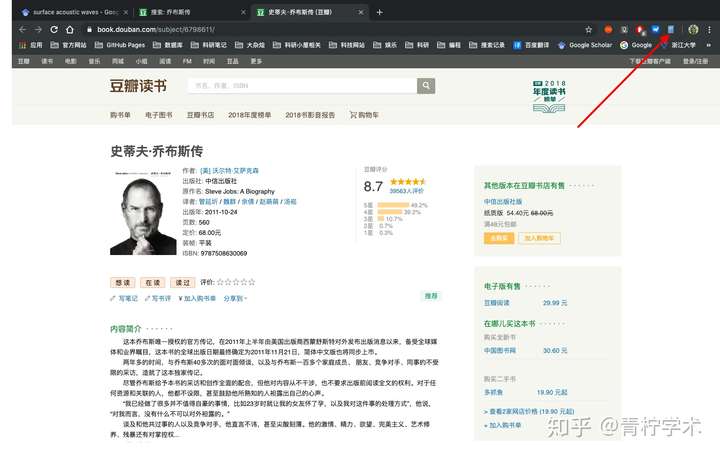
c. 豆瓣
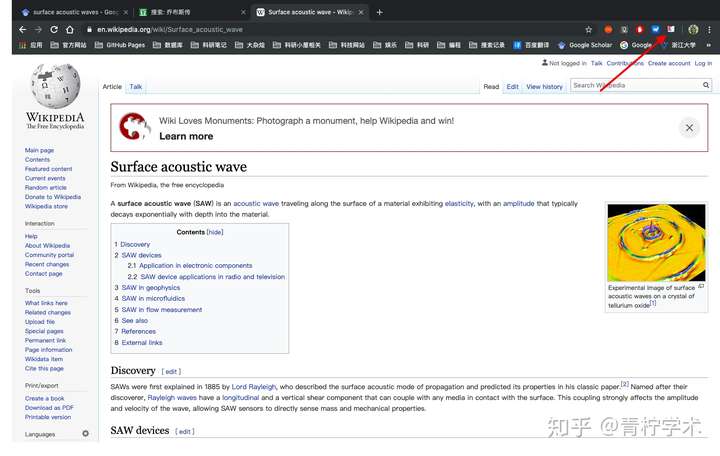
d. Wikipedia
维基百科大家用的非常多,Zotero也能够识别维基百科的搜索条目,如下图所示。
除了上面提及一些,Zotero还能识别更多其他数据库和网站,如常用的Web of Science,Youtube等等,这里就不再一一举例,大家可以自己试试。
Zotero下载99%文献
下面具体介绍如何将Sci-Hub作为PDF解析器!
设置Sci-Hub作为PDF解析器
PDF resolvers的设置在Zotero的Config Editor中。
我们打开Zotero的首选项,进入Advanced-->Config Editor。
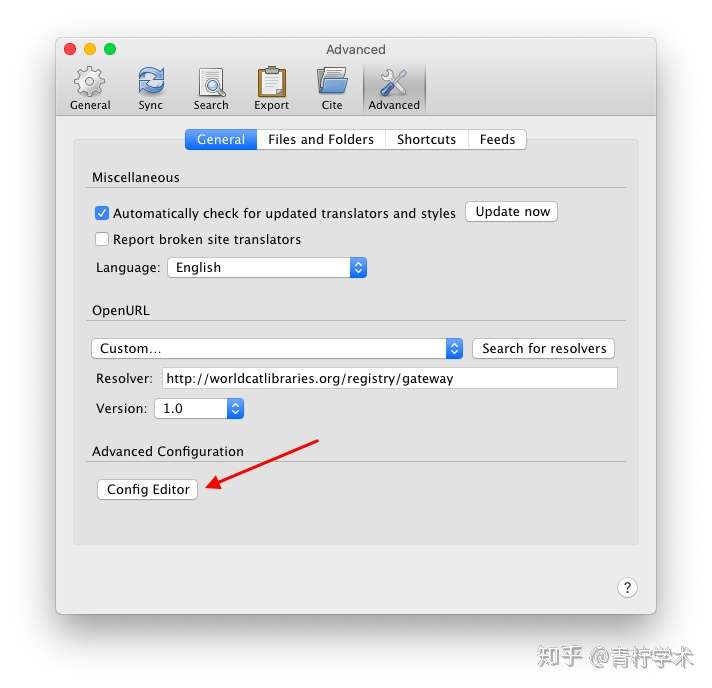
搜索extensions.zotero.findPDFs.resolvers,如下。
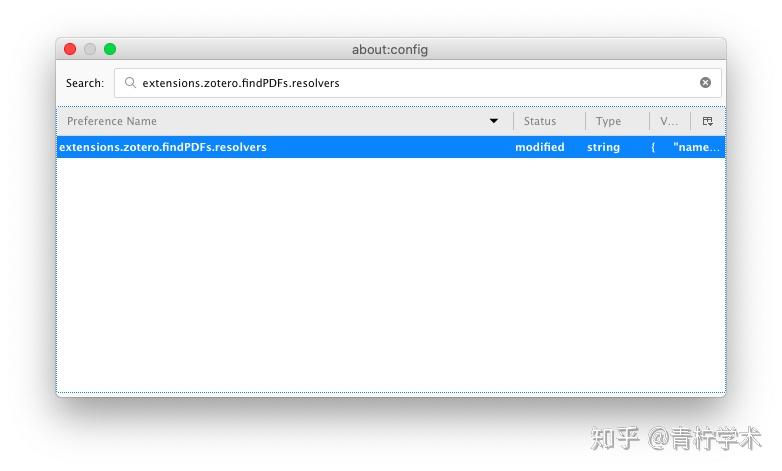
双击extensions.zotero.findPDFs.resolvers,默认情况下是只有一对[]。
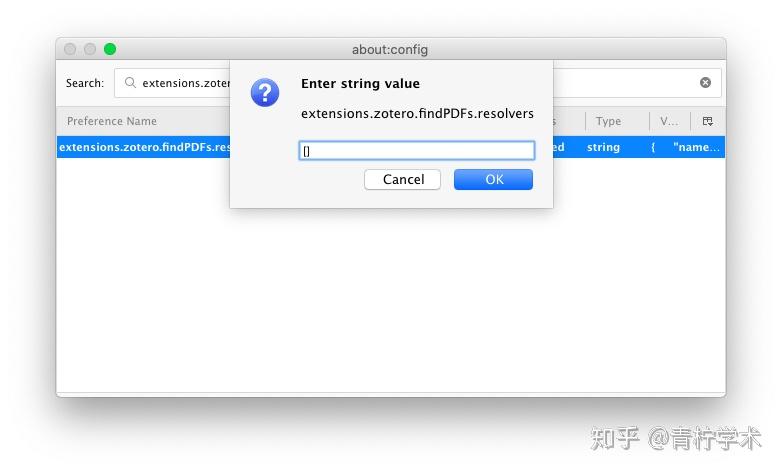
删除[],并将以下代码粘贴进去。
{
"name":"Sci-Hub",
"method":"GET",
"url":"https://sci-hub.ren/{doi}",
"mode":"html",
"selector":"#pdf",
"attribute":"src",
"automatic":true
}然后点击OK。
到此就成功将Sci-Hub配置为PDF解析器了,也就是说替代了默认的Unpaywall。
现在,无需重启Zotero,即可调用Sci-Hub免费下载文献了。
这里顺便提三点:
- 在
"url":"https://sci-hub.ren/{doi}"中,目前可用的域名有.tw、.ren、.si、.shop,大家可以挑选其中一个,哪个用起来体验更好就用哪个。(当然,由于Sci-Hub经常更换域名,保不准改天哪个域名就挂了,或者有新的域名出来,因此此处的代码未来也会根据需要进行更新) - 从
"url":"https://sci-hub.ren/{doi}"还能看到一点。由于Sci-Hub是通过doi下载文献的,因此该PDF解析器也需要doi。也就说你的文献必须要有doi,如果doi是空缺的,便无法通过PDF解析器免费下载文献。幸运的是,对于缺失doi的文献,我们可以通过插件zotero-shortdoi插件一键抓取doi。 "automatic":true,如果设置为true,Zotero会自动下载保存到Zotero中的文献的PDF。比如你用Zotero Connector保存了一些文献到Zotero,它便会自动帮你从Sci-Hub下载文献,并附在相应文献条目下。如果你不需要自动下载,可以设置为"automatic":false。
使用方法前面介绍过,主要有两种:
第一种:Zotero Connector
通过Zotero Connector保存的文献,会自动下载PDF,无需任何操作。(看不到进度条,下载速度取决于网速)
第二种:Find Available PDF
选中单篇或者多篇文献,手动点击右键菜单中的Find Available PDF,会弹出单独的窗口显示下载进度。同样,下载速度取决于网络速度。
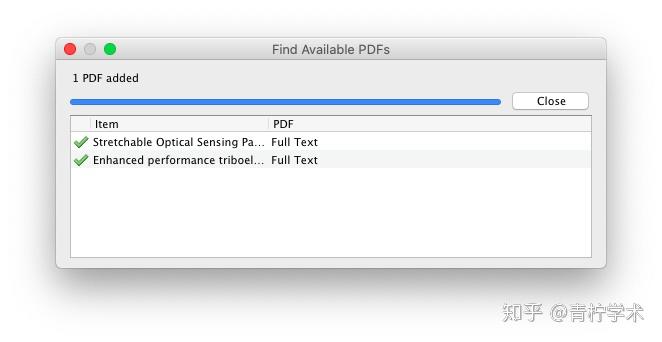
关于下载速度取决于网络速度有下面两点需要注意;
- 如果你未开启任何网络加速器(比如梯z),即正常使用网络,可以认为Find Available PDF的进度接近你手动从Sci-Hub下载文献的速度。大家应该都体验过,不开启加速器的情况下,Sci-Hub的访问速度还是比较慢的,甚至有时候PDF加载不出来。
- 假如你开启了加速器,推荐使用全局代理模式,而不是PAC模式,因为两种情况下Find Available PDF的进度差异比较大(当然如果你不介意下载速度,使用PAC模式也是可以的)。不过提醒一下,下载完文献,记得切回到PAC模式,因为全局模式下Zotero无法同步文献到坚果云。
可以看到,搭配Sci-Hub后,Zotero变得更加完美了!这就是开源软件的魅力,它能带来无限的想象空间。
本文所有内容为知乎作者青柠学术整理而来。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!